1. DockerOperator를 사용하는 이유
- 상황에 따라 버전이 다른 라이브러리를 사용하는 경우가 많고, airflow에서 기본적으로 지원하지 않는 라이브러리를 사용하는 경우도 있다.
- 이럴때 운영 줄인 airflow 서버에 라이브러리를 설치해야하는데, 하나의 서버에서 다양한 라이브러리와 버전을 모두 제공할 수 없다.
- 그리고 특정 라이브러리를 설치하는 경우에 심각한 경우 Airflow가 작동하지 않는 경우도 있다.
- 따라서 Airflow와 머신 환경에 종속되지 않고 컨테이너 환경에서 dag를 실행하도록 하면 많은 문제가 해결된다.
2. 실습 환경
- airflow 3.1.0 버전에서 실행하였다.
- airflow 2.x.x 버전과 DockerOperator에서 auto_remove를 설정하는 것이 차이가 있다.
- 2버전에서는 true와 false로 자동 삭제를 설정한다.
- 3버전에서는 success, never, force로 설정한다.
- 아래의 링크에서 내용을 확인할 수 있다.
airflow.providers.docker.operators.docker — apache-airflow-providers-docker Documentation
airflow.apache.org
3. DockerOperator 실행 실습
- 아래의 dag를 사용하여 실습을 진행한다.
from datetime import timedelta
from airflow import DAG
from airflow.providers.docker.operators.docker import DockerOperator
from airflow.operators.bash import BashOperator
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': '2025-09-20',
'retries': 1,
'retry_delay': 30,
}
dag = DAG(
'docker_test',
default_args=default_args,
description='echo "hello, world!"',
schedule=timedelta(days=1),
)
t1 = BashOperator(
task_id='echo_host',
bash_command='whoami',
dag=dag
)
t2 = DockerOperator(
task_id='echo_container',
image='ubuntu:22.04',
container_name='test_echo_container',
auto_remove='success',
command="whoami",
hostname='docker_test',
dag=dag
)
t1 >> t2
- 아마도 높은 확률로 BashOperator는 작동했지만 DockerOperator에서 문제가 발생할 것이다.
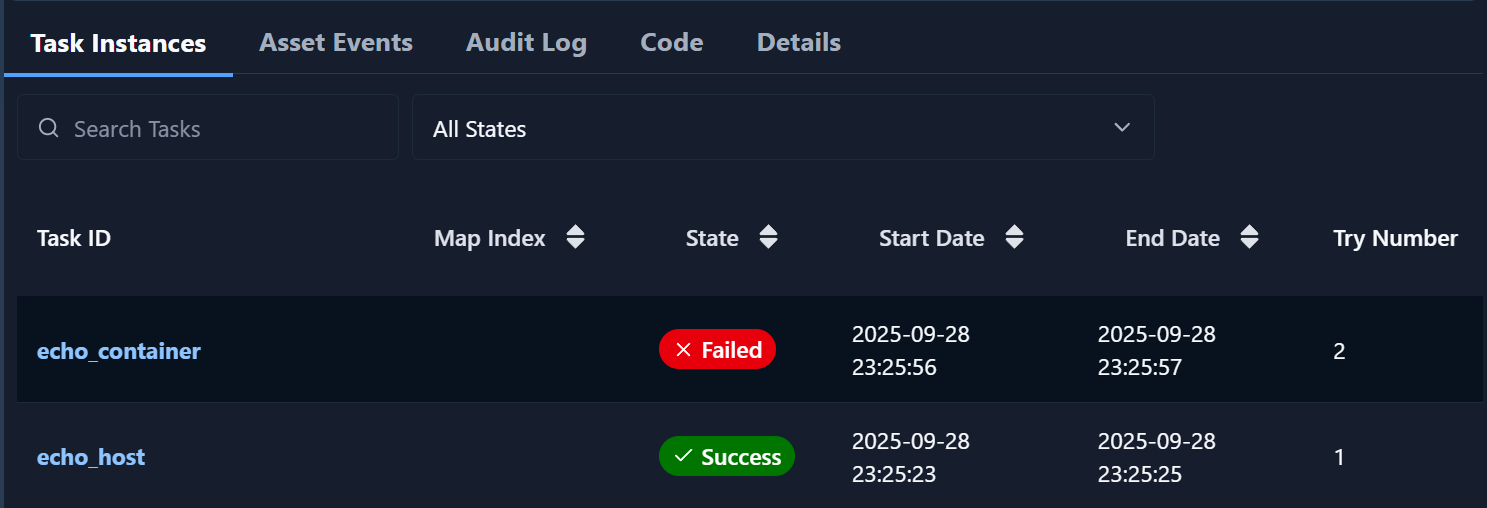
- 아래와 같은 에러메세지가 있을텐데 쉽게 말하자면 컨테이너를 생성할 docker와 통신하지 못해서 발생하는 문제이다.
ERROR - Failed to establish connection to Docker host unix://var/run/docker.sock: Error while fetching server API version: ('Connection aborted.', FileNotFoundError(2, 'No such file or directory'))
- docker compose로 구축한 airflow의 컨테이너와 docker가 통신할 수 있도록 실습하는 pc에 설치되어있는 docker와 연결할 수 있도록 docker compose yaml에서 아래와 같은 설정을 하자.
x-airflow-common:
&airflow-common
......
environment:
......
volumes:
......
# 이 경로를 설정하자
- /var/run/docker.sock:/var/run/docker.sock
- airflow를 아래의 명령어로 환경 변수 변경 값을 적용해 다시 실행하자
docker compose down && docker compose up -d
- 이제는 DockerOperator의 작업도 정상적으로 실행된 것을 알 수 있다.
- 만약 컨테이너가 제대로 실행됐는지 궁금하다면 dag에서 auro_remove='never'로 바꾸고 실행해서 확인할 수 있다.
- 변경 후 dag를 실행하면 실습하는 pc의 docker에 아래와 같은 종료된 컨테이너가 있는 것을 확인할 수 있다.
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9f573e521d55 ubuntu:22.04 "whoami" 39 seconds ago Exited (0) 38 seconds ago
'데이터 시스템 구축 정보 공유 > airflow' 카테고리의 다른 글
| 3. Airflow 3.1.0 버전에서 dag가 실행되지 않는 문제 (1) | 2025.09.28 |
|---|---|
| 2. docker를 사용한 airflow 설치 (0) | 2024.01.11 |
| 1. Airflow란? (0) | 2022.07.31 |